If you want to prevent Google from including certain pages of your website in search results, you can tell Google not to index them. By doing so, you can ensure that only the right page you want are accessible for visitors. In this article, I will explain how to tell Google to not index a page on your website using the “noindex” tag or the “robots.txt” file.
Table of Contents:
What pages should I exclude from google index?
There are a few types of pages that you may want to exclude from Google’s index:
Duplicate content: If you have multiple pages on your website that contain the same or similar content, you may want to exclude some of these pages from Google’s index to avoid a duplicate content penalty. This can happen if you have different versions of the same page for different languages or regions, for example.
Low-quality or thin content: Pages with little or no valuable content, such as pages with only a few sentences or with content that is automatically generated, may not provide value to users and may be seen as low-quality by search engines. It’s generally a good idea to exclude these pages from Google’s index to avoid harming your website’s overall search rankings.
Private or sensitive information: Pages with private or sensitive information, such as personal data, financial information, or confidential business information, affiliate links should be password-protected or excluded from Google’s index to avoid exposing this information to the public.
Unimportant or outdated pages: Pages that are no longer relevant or important to your website’s overall goals, such as old blog posts or pages that have been replaced by newer content, may not need to be indexed by Google.
What pages I should exclude from indexing for ecommerce website
As an ecommerce website owner, there are a few types of pages that you may want to exclude from Google’s index. Here are some examples:
Out of stock or discontinued products: Pages for products that are no longer available or have been discontinued should be excluded from Google’s index to avoid frustrating users who may click on search results for these products only to find out they are no longer available.
Product pages with duplicate content: If you sell products that are also available on other ecommerce websites, it’s important to avoid duplicate content issues. You should exclude any product pages that contain identical or nearly identical content to other pages on your own site or on other websites. Hint- you can use canonical tag to tell Google which is your main page.
Low-quality or thin content pages: Pages with little or no valuable content, such as product pages with only a few sentences or with content that is automatically generated, may not provide value to users and may be seen as low-quality by search engines.
Test pages: Pages that are used for testing or development purposes should not be indexed by search engines, as they may provide a poor user experience and contain unfinished or irrelevant content.
It’s important to regularly review your blog / ecommerce website and identify any pages that may not need to be indexed by search engines. By doing so, you can help ensure that your website’s content is high-quality, relevant, and valuable to users, which can improve your overall search rankings and drive more targeted traffic to your site.
How Google indexing pages
Google indexing pages using crawlers, also known as spiders or bots. These crawlers follow links from one page to another and collect information about each page they visit. This information is then added to Google’s index, which is a massive database of web pages and their content.
When a crawler visits a web page, it analyses the content of the page and extracts information about the page’s topic, keywords, and other relevant information. This information is then used to determine where the page should be ranked in Google’s search results.
In addition to analysing the content of individual pages, Google’s crawlers also take into account factors like the quality and relevance of external links pointing to the page, the page’s loading speed and mobile-friendliness, the overall authority and trustworthiness of the website. Short named as E-E-A-T (Experience, Expertise, Authoritativeness and Trustworthiness).
Once a page has been crawled and indexed by Google, it can be displayed in the search results for relevant search queries. However, Google’s algorithms are constantly changing and updating, so it’s important to follow best practices for on-page optimization, link building, and other SEO strategies to ensure that your website is properly indexed and ranked in Google’s search results.
What is robots.txt file?
The robots.txt file is a file that is placed in the root directory of a website and is used to communicate with web robots and other automated agents that visit the website. The file provides instructions to these agents about which pages or sections of the website they are allowed to crawl and index, and which pages or sections they should avoid.
You must know that not all robots and automated agents will follow the instructions in the robots.txt file, and it should not be used as a substitute for other website security measures to protect sensitive data. Additionally, the robots.txt file should be used in conjunction with other tools and best practices for search engine optimization (SEO).
How to use robots.txt to tell Google to bot index a page?
To use the robots.txt file to tell Google not to index a page, you need to add a “Disallow” directive for that page in your robots.txt file. Here are the steps to do this:
- If you don’t already have a robots.txt file, create one in the root directory of your website. The robots.txt file should be named “robots.txt” and should be located at the root of your website (e.g. www.yoursite.com/robots.txt).
- Add a “Disallow” directive for the page: In the robots.txt file, add a “Disallow” directive followed by the URL path of the page you want to exclude from Google’s index. For example, to exclude a page with the URL www.yoursite.com/excluded-page.html, you would add the following line to your robots.txt file:
User-agent: * Disallow: /excluded-page.htmlThis tells Google’s crawler not to visit the excluded-page.html page and not to include it in its index.
- Save and upload the robots.txt file: Once you have added the “Disallow” directive for the page you want to exclude, save the robots.txt file and upload it to the root directory of your website. You can then check that the file is correctly formatted using the robots.txt tester in the Google Search Console.
What is “noindex” tag?
The “noindex” tag is a piece of HTML code that can be included in the header of a webpage, and is used to tell search engines like Google not to index that page. When the noindex tag is included in a webpage’s header, search engine crawlers will still visit the page and follow any links on it, but they will not include the page in their search index. This means that the page will not show up in search results when someone searches for keywords related to the page’s content.
noindex tag is commonly used on webpages that contain duplicate content, low-quality content, or sensitive/private content that should not be accessible to the public. By including the noindex tag on these pages, website owners can ensure that they are not penalized by search engines for having low-quality or duplicate content, and can also prevent sensitive/private pages from showing up in search results.
How to add noindex tag in HTML page?
Open the HTML code of the page that you want to exclude from Google search results.
Locate the <head> section of the HTML code.
Add the following meta tag to the <head> section:
<meta name="robots" content="noindex">Save the changes to the HTML code.
What is “nofollow” tag
The “nofollow” tag is a piece of HTML code that can be added to a hyperlink on a webpage to tell search engines not to follow that link. When a search engine crawler encounters a hyperlink with a nofollow tag, it will not follow the link to the linked page or website.
It was introduced in 2005 as a way for website owners to combat spam and prevent search engines from penalizing their website for having links to low-quality or irrelevant websites. By using the nofollow tag on links to low-quality or irrelevant websites, website owners can prevent search engines from associating their website with those sites.
This tag does not prevent search engines from crawling the linked website or from including it in their index. It only tells search engines not to pass on any SEO value or authority from the linking website to the linked website.
When to use nofollow tag?
The nofollow tag should be used in specific situations where you do not want search engines to follow a link and pass on any SEO value or authority to the linked page. Here are some common situations where using the nofollow tag is appropriate:
User-generated content: If your website allows users to post comments or other types of user-generated content, you should use the nofollow tag on any links included in those posts. This can help prevent spam and keep your website in compliance with search engine guidelines.
Paid links: If you include paid links or sponsored content on your website, you should use the nofollow tag on those links to avoid being penalized by search engines. Google considers the use of paid links as a violation of its Webmaster Guidelines, so using the nofollow tag on these links can help protect your website’s search engine rankings.
Untrusted content: If you include links to websites that you do not trust or that are not relevant to your website’s content, you should use the nofollow tag on those links. This can help prevent search engines from associating your website with low-quality or spammy websites.
Internal links: You may also use the nofollow tag on internal links within your website to prevent search engines from passing on SEO value to pages that are not relevant to your website’s overall theme or content.
Password-protect the page
If the page you want to exclude contains sensitive information or is only intended for a specific audience, you can password-protect it. This will prevent search engines from indexing the page because they cannot access the content without a valid username and password.
Use the “noindex” HTTP header
Another way to exclude a page from Google’s index is to use the “X-Robots-Tag” HTTP header. This method is similar to using the “noindex” meta tag, but instead, you add the header to the HTTP response sent by the server. This method is more advanced and may require technical expertise to implement correctly.
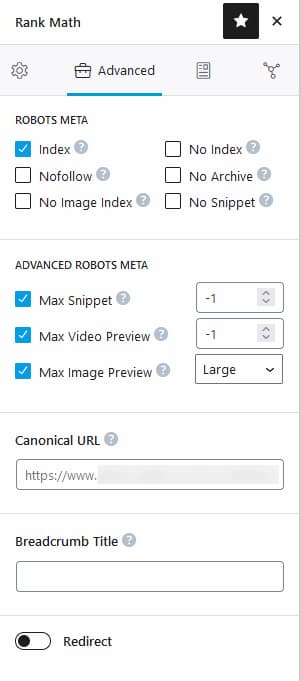
How to Tell Google to Not Index a Page for WordPress
If your website built on WordPress, then most likely you have Yoast RankMath or AIO SEO plugin installed. It is very easy to add tags for any page or post settings individually as well as to modify robots.txt file.

How to know if a page is indexed by Google?
There are a few ways to verify that pages are not indexed on Google:
- Use the site: operator: You can use the site: operator followed by the URL of the page in question to see if it’s been indexed by Google. For example, if you wanted to check if the page https://example.com/page1/ had been indexed, you would search for “site:example.com/page1/” in Google. If the page has been indexed, it will show up in the search results. If it hasn’t been indexed, it will not appear in the search results.
- Use Google Search Console: Google Search Console is a free tool that allows website owners to monitor their website’s performance in Google search. You can use the Coverage report in Google Search Console to see which pages on your website have been indexed by Google. If a page is not indexed, it will appear as “Excluded” in the Coverage report.
- Use a third-party SEO tool: There are many third-party SEO tools available that can help you monitor which pages on your website have been indexed by Google. Some popular options are Ahrefs, SEMrush, Moz, Screaming frog web crawler (software). These tools can provide detailed information on which pages have been indexed, as well as other SEO metrics like backlinks and keyword rankings.
Even if a page is not indexed by Google, it may still be accessible to users if they have the direct URL or if there are links to the page from other websites. To ensure that a page is completely hidden from search engines and users, you may need to take additional steps like using password protection or restricting access through a robots.txt file
Wrapping up: How tell Google not to index a page
You can use one of the following methods:
- Use the robots.txt file: You can create a robots.txt file and include a “Disallow” directive for the page or pages that you don’t want Google to index. This tells Google’s crawler not to visit those pages and not to include them in its index.
- Use the “noindex” meta tag: You can add a “noindex” meta tag to the head section of your page’s HTML code. This tells search engines not to index the page.
- Use the “nofollow” attribute: If you have links on your page that you don’t want search engines to follow, you can add the “nofollow” attribute to those links. This tells search engines not to follow the link to the linked page.